


Sanmayce
-
Posts
13 -
Joined
-
Last visited
Content Type
Profiles
Forums
Events
Posts posted by Sanmayce
-
-
Can we say that since v2.70 we can compare those Mpixels/s safely? For example, one fellow member one overclock.net forum shared this:

I mean he uses only 6cores/6threads (4-channel DDR3-2133) and reaches 31921 half the performance of 20cores/40threads (Max Turbo Frequency 3.3 GHz) (8-channel DDR4-1866) 62186.
My dummy calculation is 6x4.7GHz=28GHz while 40x3.3GHz=132GHz, why the speedup is 2x and not 132/28=4.7x?
I thought that speedup is linear with adding more threads, is it because you reached the maximum bandwidth? Are those 62186 equal 60GB/s RAM throughput?
-
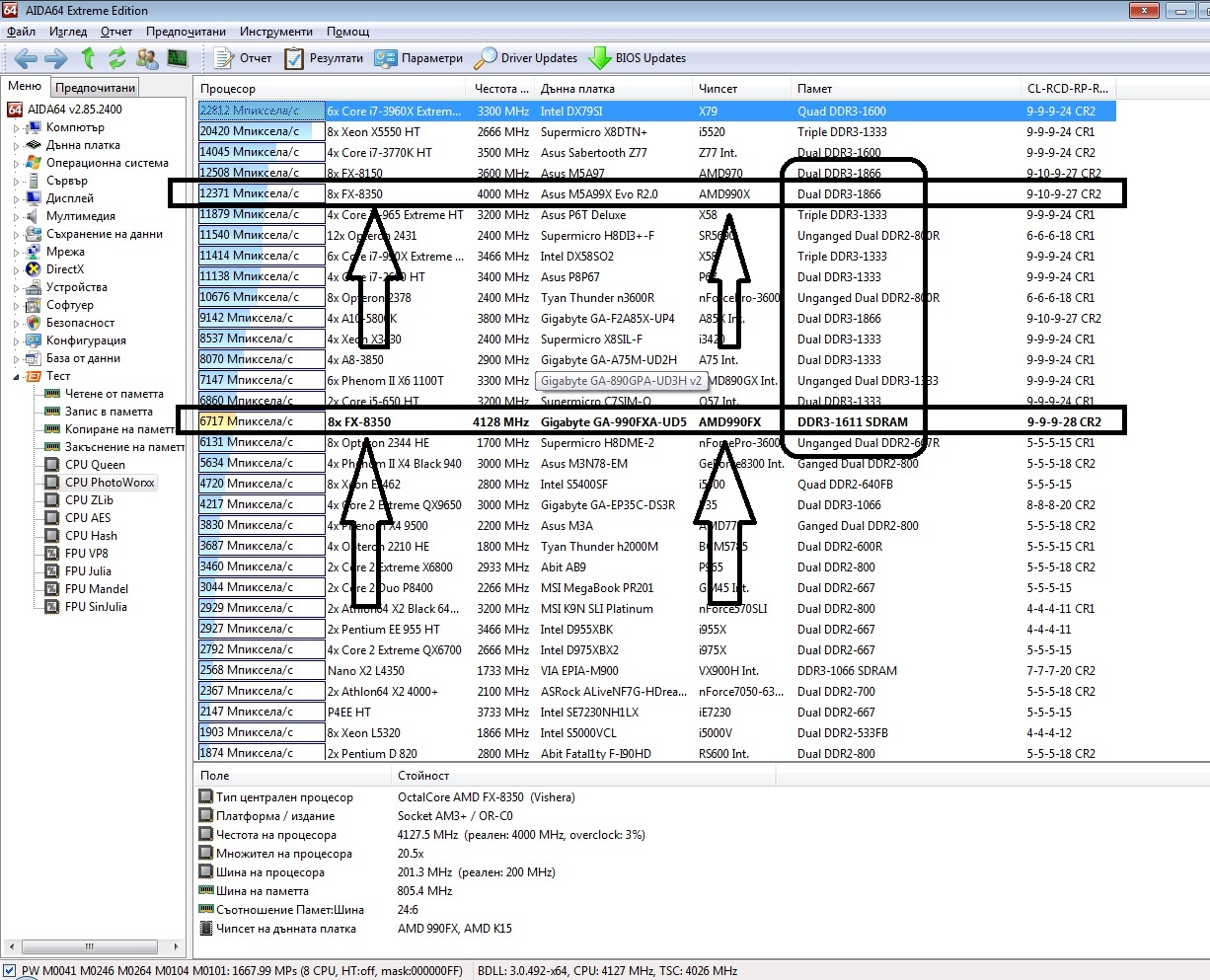
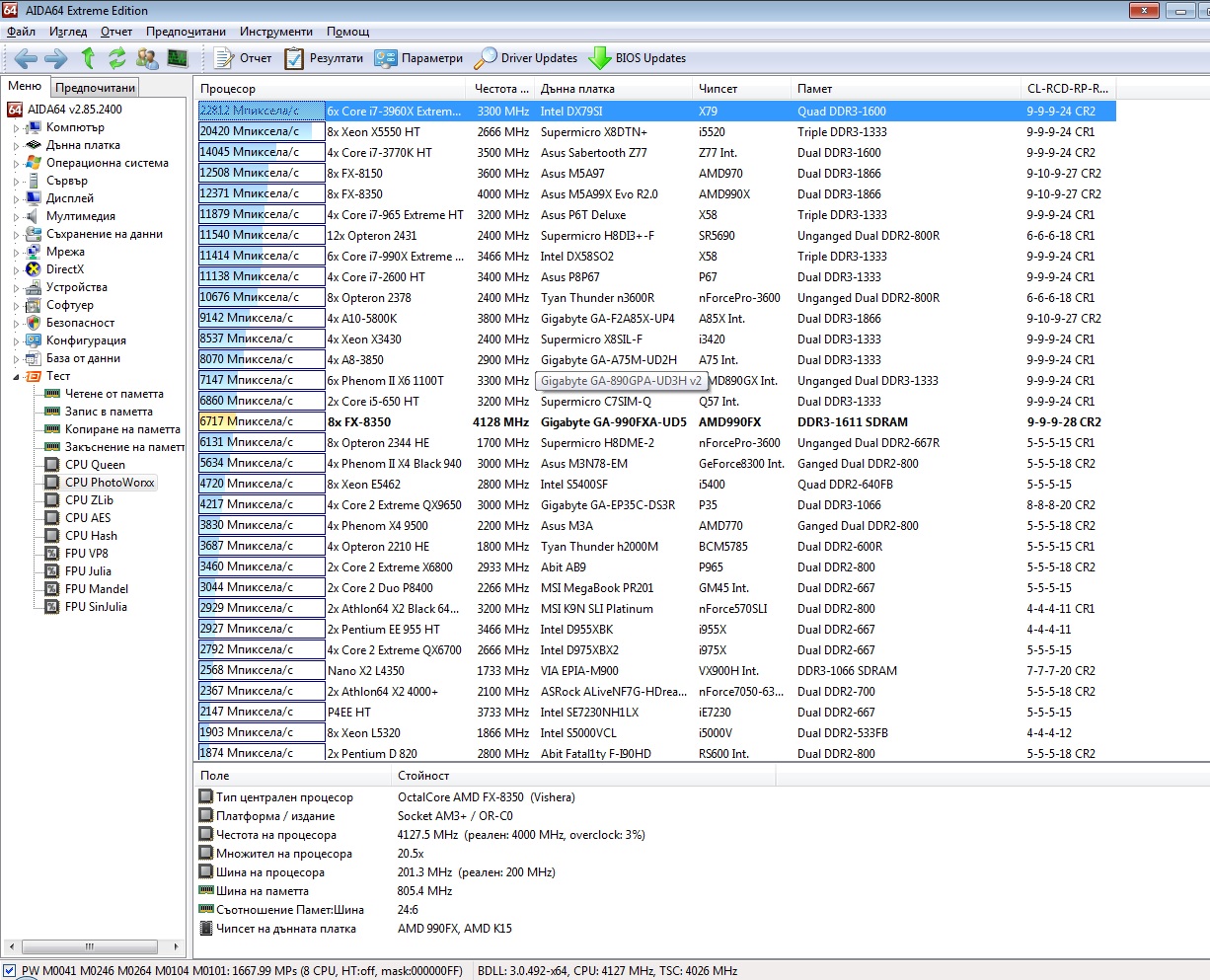
Ouch, just saw that the above screenshots show results e.g. for 4x Phenom II 20352 for the AIDA64 EE while the other AIDA64 EE shows for the same computer 5634Mpixels/s, didn't know that two different metrics were in use, how so?
-
Hi again,
can you post a snapshot of highest Photoworxx scores you know of?
I searched and found this site:
http://amdfx.blogspot.com/2012/01/aida64-benchmarks-windows-7-fx-patch.html
I found 94,910:
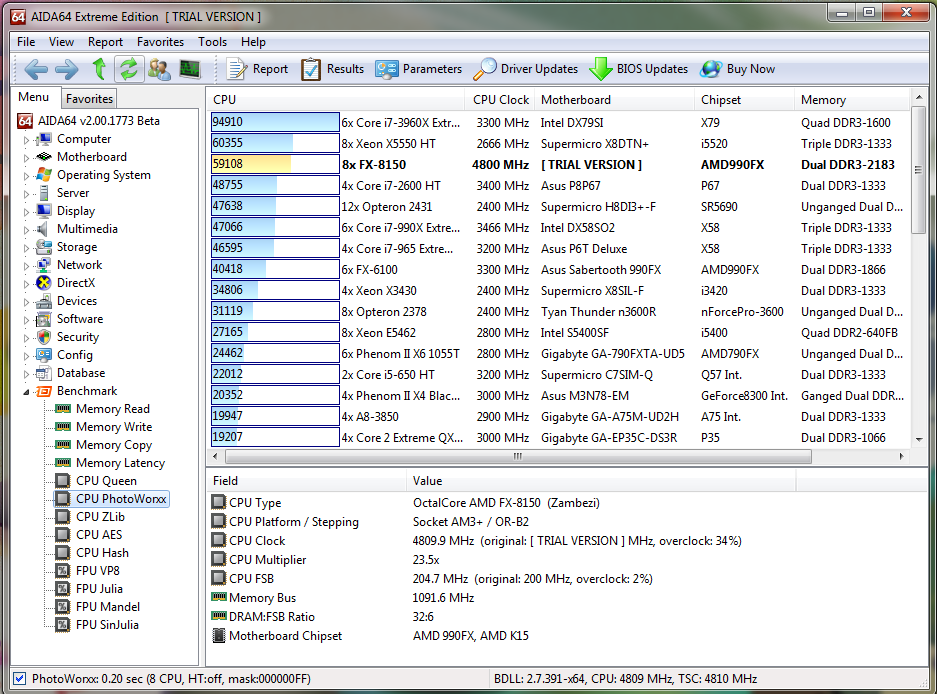
Also, please explain what causes such suspiciously low score on 5775c (here):
AMD 'Zambezi' to be 3x faster, something here seems not as it should.
-
Thanks, just one more question, according to my observation I see 2x speed increase coming only from the doubled RAM bandwidth, is it so? I didn't expect such a huge impact coming only from the bandwidth, I thought that the main bottleneck would be latency, very strange (I see 12GigaPixels/s may be 12GB/s or 36GB/s), could you clarify why that happens. Is PhotoWorxx bandwidth bound?
-
I see, it really serves well, in a way it is even better than sorting, I myself wrote in 16bit assembly picture rotator/viewer called 'Otane'. It stresses very heavily the RAM block needed to house the matrix.
By the way, is your picture big enough to stress L4, this month with help of some fellows (owning 5775C) I want to see the impact of L4 - it interests me a lot compressionwise. I intend to stress 256MB block with a BWT/LZ decompression. I will ask them to run PhotoWorxx and will compare the results with decompression ones.
-
... It is not designed to show off the underlying cache architecture performance.
That's what I had as a suggestion.
Simlpy, I wanted to see a single number reported by AIDA giving some overall impression on how the tested machine behaves in intensive REALWORLD all-caches-involved integer scenario.
-
Allow me to suggest one additional benchmark showing one of the most needed tasks in single-thread - sorting.
Whether a sorting algorithm or an actual compressor using BWT I see no big difference.
I found this thread giving some flavor of what we can expect:
http://techreport.com/forums/viewtopic.php?f=2&t=93911#p1206147
Code Name Product Cores Threads Clocks Power Release Date Notes Crystal Lake? Core i7 Extreme Edition 4 16 3.4 Ghz 95W 2016Q2 New socket. SoC. Dual channel DDR4 and 24 PCIe 4.0 lanes, 256 MB of eDRAM, unlocked Crystal Lake refresh Core i7 Extreme Edition 4 16 3.5 Ghz 95W 2016Q4 New socket. SoC. Dual channel DDR4 and 24 PCIe 4.0 lanes, 256 MB of eDRAM, unlocked Cannon Lake Core i7 Extreme Edition 6 24 3.6 Ghz 87W 2017Q3 New socket. SoC. Dual channel DDR4 and 24 PCIe 4.0 lanes, 256 MB of eDRAM, unlocked
Now, we have 128MB, next year hopefully 256MB L4, how are we gonna estimate the role of L4?
-
Those 128MB are interesting, my goal is to see how well L4 helps compression and mostly decompression when using big blocks.
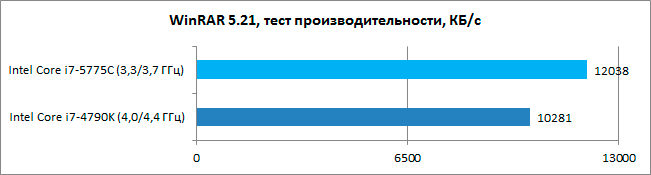
These guys showed that it helps, but they didn't say what the dictionary size was and what method they used.
With introducing L4 I wonder is AIDA64 ready to show similar scenario, I mean Zlib uses only 32KB, is there an idea of adding some heavy compressor to the benchmark roster?
-
Hi guys,
can anyone clarify the huge latency (as I see it) of L4 cache obtained on that system: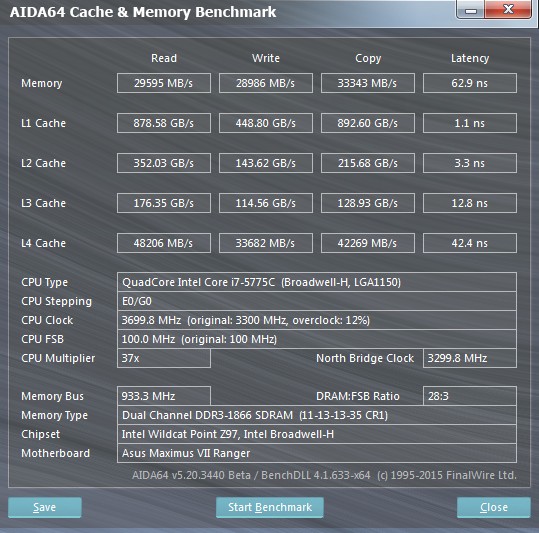
My dummy expectations were for 20ns, why 42ns?
In my view L4 performs poorly - only 20ns better than RAM. -
Thanks, the problem is my misery, I relied on forums to see how new and old CPUs fare.
There is an old Bulgarian proverb:
"The wolf's neck is tick because he does the/his work himself."
Good luck -
... letting you to try every combinations on an actual CPU ...
Thanks,
that's what I want to know L1 cache loading speed i.e. read via:
- general purpose 32bit registers;
- general purpose 64bit registers;
- XMM registers;
- YMM registers.
My suggestion, as an Everest fan, is to "retain" the single-threaded report along with the new 'modern' one.
I still cannot compare e.g. i7 4770K stock with my Core 2, allow me one last question:
What benchmarker do you use to obtain Everest-like L1 cache read speeds?
http://www.youtube.com/watch?v=kfLUBOW-yRc
Similarly to the above shown World Record 432km/h it is useful to know the 'BANDWIDTH' of the car but the need for speed is of all kinds!
As you can see at the end where speed is reduced from 400 to 200, the miserable 200km/h look/feel CASUAL - but this is the most needed diapason - I mean YMM are overkill for certain (e.g. superfast hashing) tasks - they impose some limitations (latency AFAIK) i.e. there is a price to be paid, in BUGATTI example: acceleration time, fuel consumption, vibrations, ...
Regards.
-
And thanks to the 2x widened L1 cache bandwidth of Intel Haswell, on these new processors using the new cache benchmarks of AIDA64 v3.00 you will get unusually high scores. Using Haswell, with a hint of overclock it's quite easy to cross the 1 TB/s mark for the L1 cache

We've also replaced the old cache and memory latency benchmark with a brand new one that uses a different approach, recommended by processor architecture engineers. The old memory latency benchmark used the classic forward-linear solution, so it "walked" the memory continuously, in forward direction.
Hi Fiery, glad I am that at last I found the right forum to ask what interests me as an amateur C coder.
I have been using Everest, which is one/the excellent tool. Do you intend to provide one thread L1 cache read speeds along with your new multi-threaded ones? Recently I asked on one OC forum what is the HASWELL's L1 speed and was struck by 900GB/s, does that mean 900/8=~110GB/s is the Everest like result?!
And if it is not against your policy can you say how (what optimizations are in use) Everest reports 5400MB/s Main RAM read on my Core 2 T7500 while my BURST_Read_8DWORDSi: (64MB block) offers only 4.699MB/s - your code is much faster!
// 'BURST_Read_8DWORDSi' Main Loop: .B3.3: ;;; for(; Loop_Counter; Loop_Counter--, p += 4*sizeof(uint32_t)) { ;;; hash32 = *(uint32_t *)(p+0) ^ *(uint32_t *)(p+0+Second_Line_Offset); 02ebc 8b 07 mov eax, DWORD PTR [edi] ;;; hash32B = *(uint32_t *)(p+4) ^ *(uint32_t *)(p+4+Second_Line_Offset); 02ebe 8b 77 04 mov esi, DWORD PTR [4+edi] ;;; hash32C = *(uint32_t *)(p+8) ^ *(uint32_t *)(p+8+Second_Line_Offset); 02ec1 8b 57 08 mov edx, DWORD PTR [8+edi] ;;; hash32D = *(uint32_t *)(p+12) ^ *(uint32_t *)(p+12+Second_Line_Offset); 02ec4 8b 4f 0c mov ecx, DWORD PTR [12+edi] 02ec7 33 04 1f xor eax, DWORD PTR [edi+ebx] 02eca 33 74 1f 04 xor esi, DWORD PTR [4+edi+ebx] 02ece 33 54 1f 08 xor edx, DWORD PTR [8+edi+ebx] 02ed2 33 4c 1f 0c xor ecx, DWORD PTR [12+edi+ebx] 02ed6 83 c7 10 add edi, 16 02ed9 4d dec ebp 02eda 75 e0 jne .B3.3Also can you share how the interleaved (i.e. halving the memory pool and reading in parallel) way of reading MAIN/L1 behaves on HASWELL? I hate the fact that cannot play with new toys myself.
Memory pool starting address: 00DF0040 ... 64 byte aligned, OK Info1: One second seems to have 998 clocks. Info2: This CPU seems to be working at 2,191 MHz. Fetching/Hashing a 64MB block 1024 times i.e. 64GB ... BURST_Read_4DWORDS: (64MB block); 65536MB fetched in 15132 clocks or 4.331MB per clock BURST_Read_8DWORDSi: (64MB block); 65536MB fetched in 13946 clocks or 4.699MB per clock FNV1A_YoshimitsuTRIADiiXMM: (64MB block); 65536MB hashed in 13572 clocks or 4.829MB per clock !!! FLASHY-SLASHY: OUTSPEEDS THE INTERLEAVED 8x4 READ !!! FNV1A_YoshimitsuTRIADii: (64MB block); 65536MB hashed in 14399 clocks or 4.551MB per clock !!! INTERLEAVED !!! FNV1A_YoshimitsuTRIAD: (64MB block); 65536MB hashed in 15912 clocks or 4.119MB per clock !!! NON-INTERLEAVED !!! CRC32_SlicingBy8: (64MB block); 65536MB hashed in 71588 clocks or 0.915MB per clock
i7-5775C L4 cache performance
in Benchmarking, system performance
Posted
Thanks for the clarification.
My next machine will have AMD Zen if they manage to offer 32threads and outperform 5960x (in my 16-threaded_Kazahana_vs_Wikipedia_fuzzy_search_torture).
Personally, I find the RAM torturing (random accesses beyond LLC) by all available threads very inspirational - it feels like exploring the view while walking on the edge of a cliff - when one is all-attention.
I fear that AMD Zen will face similar to your 40-threaded system RAM bottleneck.